R語言深度學習入門 H2O包安裝報錯解決、數據連接與人工智能基礎開發(fā)
1. 深度學習入門:為何選擇R與H2O
在人工智能浪潮中,R語言憑借其卓越的統(tǒng)計計算和數據可視化能力,已成為數據科學與機器學習領域的重要工具。對于希望進入深度學習領域的R用戶而言,H2O包提供了一個強大、高效且易于上手的解決方案。H2O是一個開源、分布式的內存機器學習平臺,它通過R、Python、Scala等接口,讓用戶能夠輕松構建深度學習模型,而無需深入了解底層復雜的分布式系統(tǒng)或GPU編程。
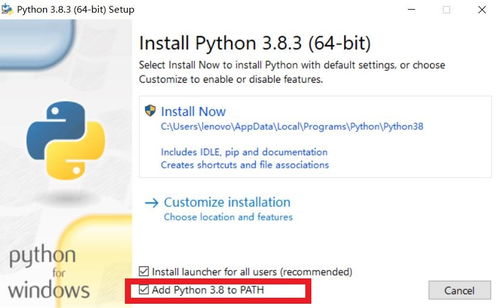
2. H2O包安裝與常見報錯解決
2.1 基礎安裝
在R中安裝H2O通常很簡單,可以直接從CRAN安裝:
install.packages("h2o")2.2 常見報錯及解決方案
報錯1:Java環(huán)境問題
H2O依賴于Java環(huán)境。如果系統(tǒng)未安裝合適版本的Java(通常需要Java 8或11),會報錯。
解決:
- 訪問Oracle或OpenJDK官網下載并安裝Java。
- 安裝后,在R中設置Java路徑(如果需要):
`r
Sys.setenv(JAVA_HOME = "你的Java安裝路徑")
`
報錯2:依賴包沖突或缺失
在安裝過程中,可能會因其他包版本不兼容而失敗。
解決:
- 確保R版本較新(建議4.0以上)。
- 嘗試單獨安裝依賴包,如 RCurl、rjson、statmod 等。
- 使用 install.packages 時,添加 dependencies = TRUE 參數。
報錯3:網絡問題導致下載失敗
解決:
- 檢查網絡連接,或嘗試更換CRAN鏡像:
`r
chooseCRANmirror() # 選擇其他鏡像
`
- 也可以直接從H2O官網下載壓縮包進行本地安裝。
報錯4:內存不足
H2O啟動時會分配一定內存,如果系統(tǒng)內存不足,會初始化失敗。
解決:
- 在啟動H2O集群時,手動指定較小的內存(如 max<em>mem</em>size = "2G")。
2.3 驗證安裝
安裝后,使用以下代碼驗證是否成功:
library(h2o)
h2o.init() # 初始化一個本地H2O集群如果成功,你將看到H2O集群的版本信息、內存分配等狀態(tài)信息。
3. 接入H2O包并連接數據集
3.1 初始化H2O集群
在開始任何分析之前,必須先初始化H2O。這將在本地或遠程啟動一個集群。
`r
library(h2o)
# 初始化,指定內存為4GB,禁止自動打印進度(nthreads = -1 表示使用所有可用CPU核心)
h2o.init(maxmemsize = "4G", nthreads = -1)`
3.2 數據導入與連接
H2O可以處理多種數據源。最常見的是將R的data.frame轉換為H2O Frame(H2O的分布式數據格式)。
從R數據框導入:
`r
# 使用內置數據集或你自己的數據框
data(iris)
iris_h2o <- as.h2o(iris)`
直接讀取文件:
H2O支持直接讀取CSV、Excel(通過URL或路徑)等格式。
`r
# 從本地文件讀取
filepath <- "path/to/your/data.csv"
datah2o <- h2o.importFile(file_path)
從網絡URL讀取(例如,從H2O的示例數據集)
url <- "https://h2o-public-test-data.s3.amazonaws.com/smalldata/iris/iriswheader.csv"
datah2o <- h2o.importFile(url)`
3.3 數據探索
轉換后,你可以像使用R數據框一樣進行基本探索,但需使用H2O的函數。
`r
# 查看維度
h2o.dim(iris_h2o)
查看列名
h2o.colnames(iris_h2o)
查看摘要統(tǒng)計
h2o.describe(iris_h2o)
查看前幾行
h2o.head(iris_h2o)`
4. 人工智能基礎軟件開發(fā):構建你的第一個深度學習模型
以經典的鳶尾花(Iris)數據集為例,構建一個簡單的深度學習分類模型。
4.1 數據準備
`r
# 分割數據為訓練集和測試集(70%訓練,30%測試)
splits <- h2o.splitFrame(iris_h2o, ratios = 0.7, seed = 123)
train <- splits[[1]]
test <- splits[[2]]
定義預測變量(特征)和響應變量(目標)
y <- "Species" # 我們要預測的列
x <- setdiff(h2o.colnames(train), y) # 除Species外的所有列作為特征`
4.2 訓練深度學習模型
使用h2o.deeplearning函數。這里使用一個簡單的多層感知機(MLP)結構。
`r
# 訓練模型
model <- h2o.deeplearning(
x = x, # 特征列名
y = y, # 目標列名
trainingframe = train, # 訓練數據
validationframe = test, # 驗證數據(可選)
hidden = c(10, 10), # 兩個隱藏層,每層10個神經元
epochs = 50, # 訓練輪數
seed = 123 # 隨機種子,確保可重復性
)`
4.3 模型評估與預測
`r
# 查看模型摘要
print(model)
在測試集上評估性能
performance <- h2o.performance(model, newdata = test)
print(performance)
進行預測
predictions <- h2o.predict(model, test)
h2o.head(predictions)`
4.4 模型保存與加載(用于軟件開發(fā)部署)
`r
# 保存模型到本地
modelpath <- h2o.saveModel(model, path = "./mymodel", force = TRUE)
加載已保存的模型
loadedmodel <- h2o.loadModel(modelpath)
使用加載的模型進行預測
newpredictions <- h2o.predict(loadedmodel, test)`
5. 與展望
通過以上步驟,我們完成了在R語言環(huán)境中,使用H2O包進行深度學習的基礎流程:從解決安裝難題、成功啟動集群、導入數據,到構建、評估并保存一個深度學習模型。H2O的強大之處在于其易用性、可擴展性以及對生產環(huán)境的友好支持(如MOJO/POJO模型導出,便于Java環(huán)境部署)。
作為人工智能基礎軟件開發(fā)的一部分,你可以將此流程封裝成函數、開發(fā)Shiny應用交互界面,或集成到更大的數據分析管道中。H2O還支持自動機器學習(AutoML)、網格搜索調參、多種算法(如GBM、隨機森林、GLM等),為在R中開展更復雜、更高效的AI項目奠定了堅實基礎。
注意:完成所有操作后,記得關閉H2O集群以釋放資源:`r
h2o.shutdown(prompt = FALSE)`
如若轉載,請注明出處:http://m.aprenergy.com.cn/product/40.html
更新時間:2026-04-08 19:00:01